Selected papers
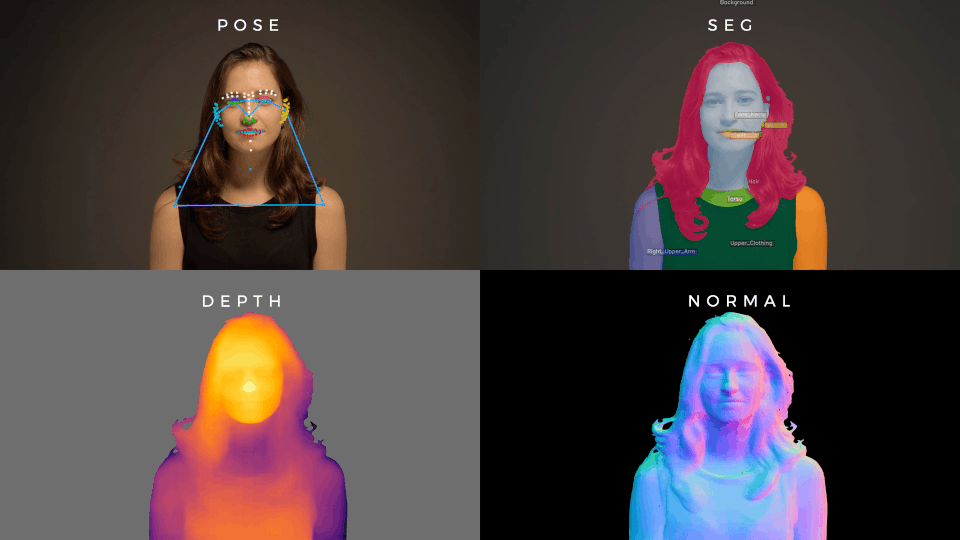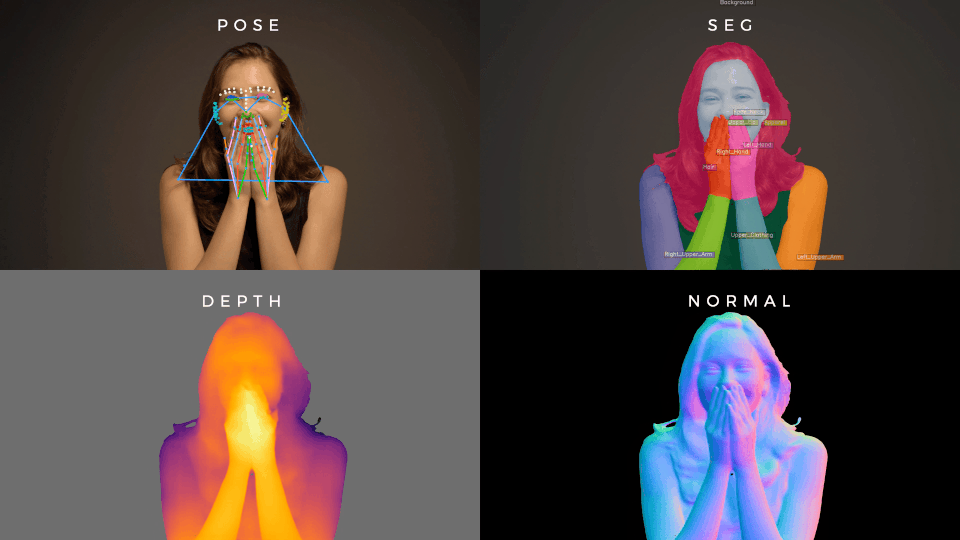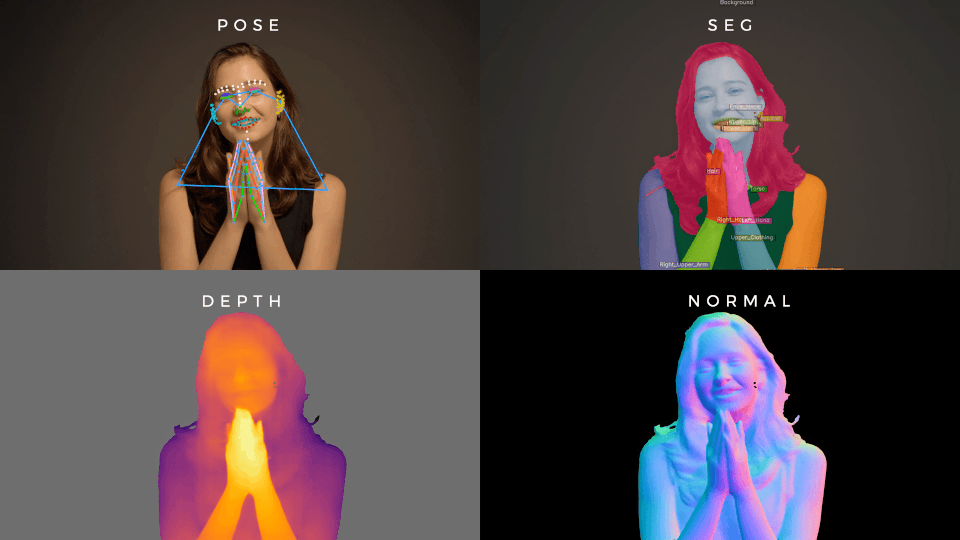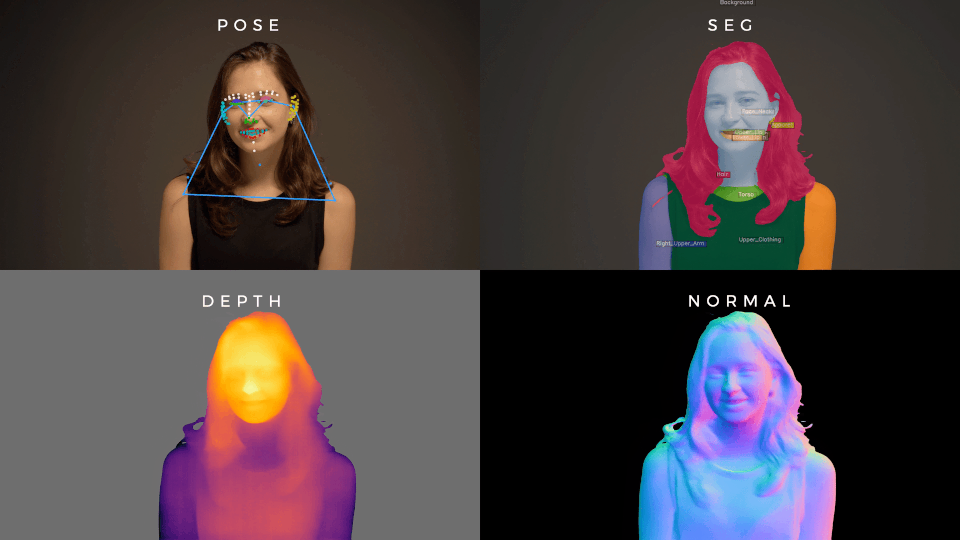
Foundation for human vision models
Rawal Khirodkar, Timur Bagautdinov, Julieta Martinez, Su Zhaoen, Austin James, Peter Selednik, Stuart Anderson, Shunsuke Saito
Sapiens: Foundation for Human Vision Models.
In ECCV 2024 (best paper award candidate)
A very large MAE that, when fine-tuned, gets state of the art performance on a wide range of human vision tasks.
Neural network compression
Julieta Martinez*, Jashan Shewakramani*, Ting Wei Liu*, Ioan Andrei Bârsan, Wenyuan Zeng, and Raquel Urtasun.
Permute, Quantize, and Fine-tune: Efficient Compression of Neural Networks.
In CVPR 2021 (oral presentation)
We search for functionally-equivalent, yet easier to compress networks to achieve state-of-the-art memory-to-accuracy tradeoffs in image classification and object detection.
Joint localization, perception, and prediction
John Phillips, Julieta Martinez, Ioan Andrei Bârsan, Sergio Casas, Abbas Sadat, and Raquel Urtasun.
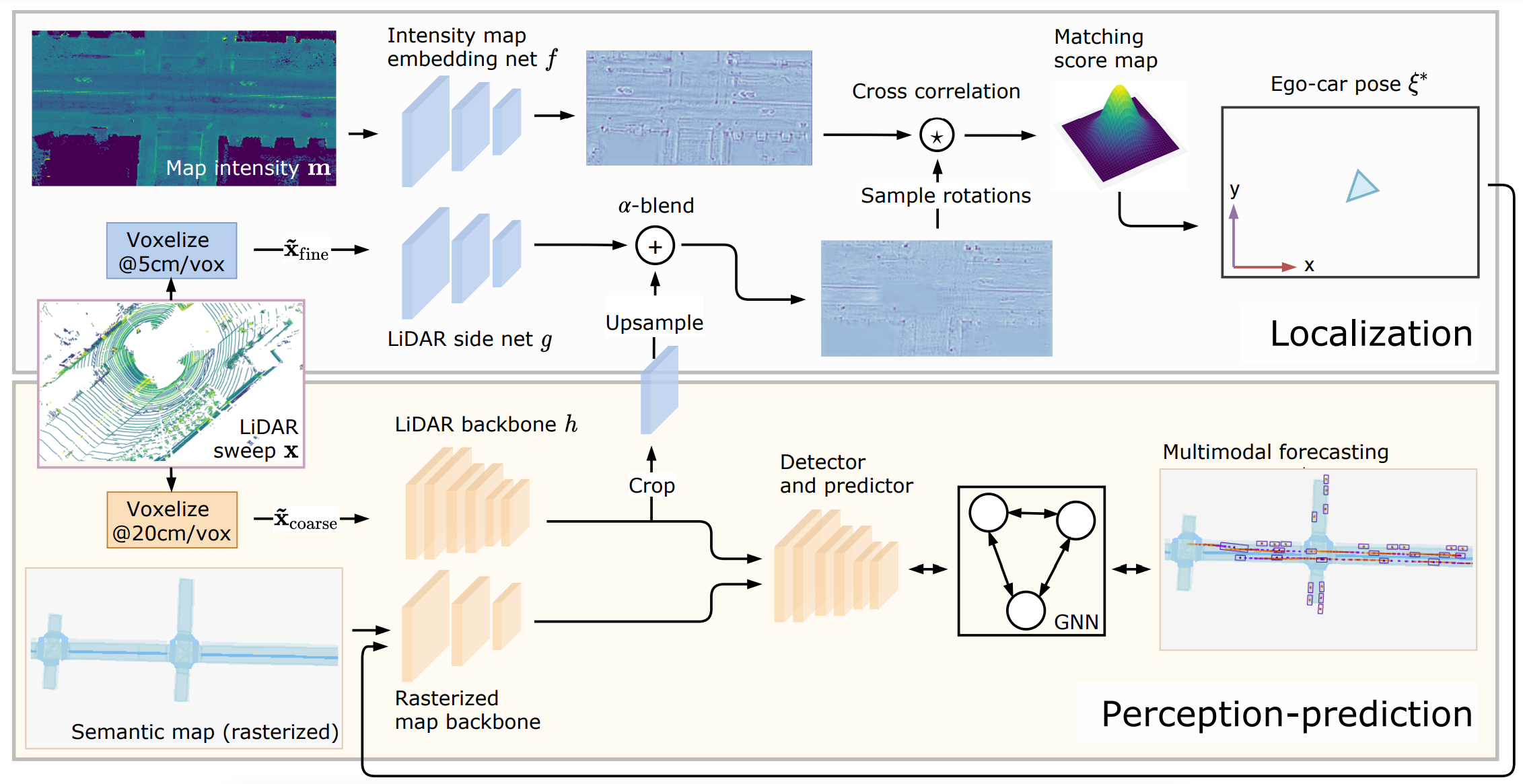
Deep Multi-Task Learning for Joint Localization, Perception, and Prediction.
In CVPR 2021
We design an architecture that jointly performs vehicle ego-localization, object detection, and motion forecasting.

Pit30M
Julieta Martinez, Sasha Doubov, Jack Fan, Ioan Andrei Bârsan, Shenlong Wang, Gellért Máttyus, and Raquel Urtasun.
Pit30M: A Benchmark for Global Localization in the Age of Self-Driving Cars.
In ICRA 2020 (best application paper runner-up)
We propose a dataset of 30 million images and LiDAR pairs to benchmark localization at city scale.
Low-memory localization
Xinkai Wei*, Ioan Andrei Bârsan*, Shenlong Wang*, Julieta Martinez, and Raquel Urtasun.
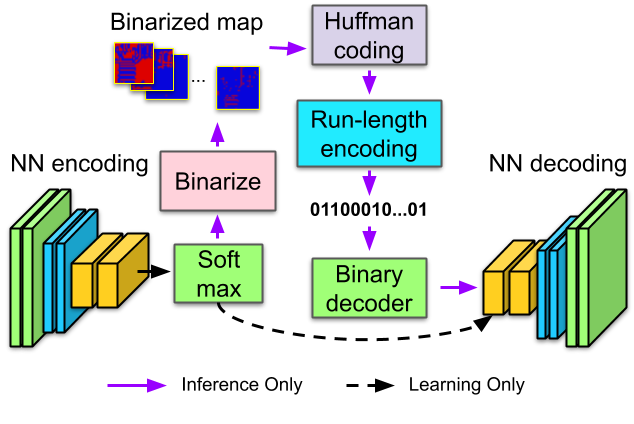
Learning to Localize through Compressed Binary Maps.
In CVPR 2019
We train neural networks to learn very low-memory maps useful for localization in self-driving.
Faster and more accurate compressed nearest neighbour search
Julieta Martinez, Shobhit Zakhmi, Holger H. Hoos and James J. Little.
LSQ++: lower running time and higher recall in multi-codebook quantization.
In ECCV 2018
We benchmark multi-codebook quantization (MCQ) approaches on an equal footing and propose two improvements that make MCQ faster and more accurate.
3d pose baseline
Julieta Martinez, Rayat Hossain, Javier Romero and James J. Little.
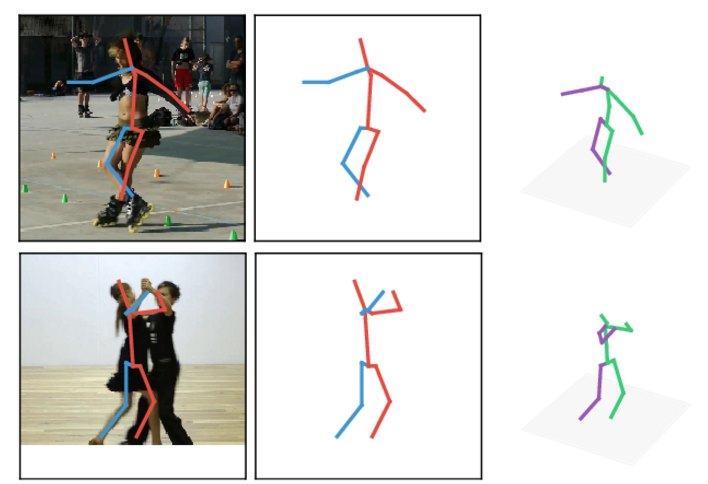
A simple yet effective baseline for 3d human pose estimation.
In ICCV 2017 (28.9% acceptance rate)
We propose a simple deep learning baseline for 3d human pose estimation that outperforms the state of the art.
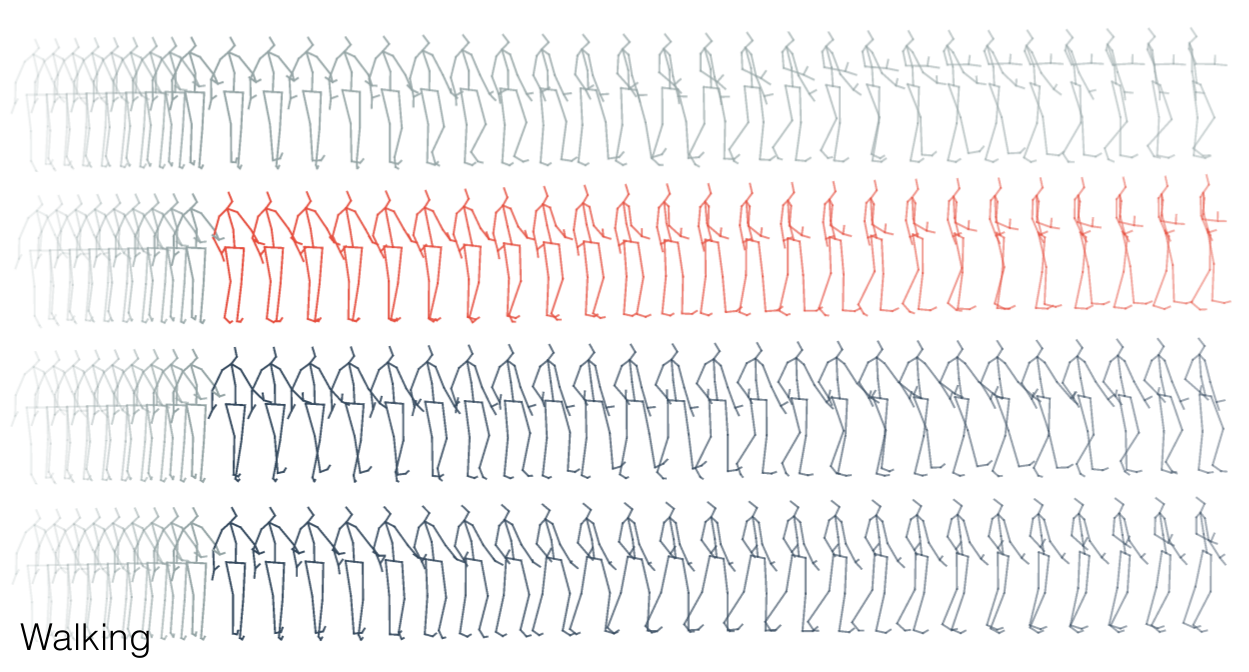
Human motion prediction
Julieta Martinez, Michael J. Black, Javier Romero.
On human motion prediction using recurrent neural networks.
In CVPR 2017 (29.84% acceptance rate)
We take a close look at deep recurrent approaches for human motion prediction, and propose a simple and scalable architecture that outperforms the state of the art.
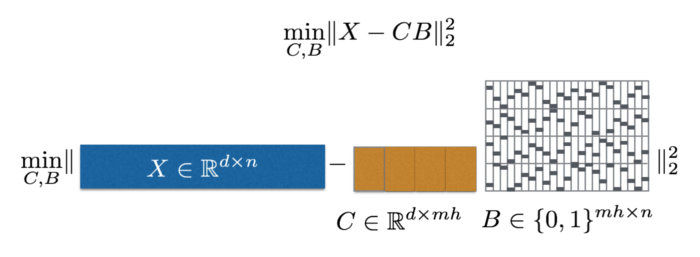
Compressed nearest neighbour search
Julieta Martinez, Joris Clement, Holger H. Hoos, James J. Little.
Revisiting additive quantization.
In ECCV 2016 (26.6% acceptance rate)
Additive quantization (AQ) is a promising vector compression approach for large-scale approximate nearest neighbour search. We introduce an optimization method for AQ that pushes it beyond the state of the art.
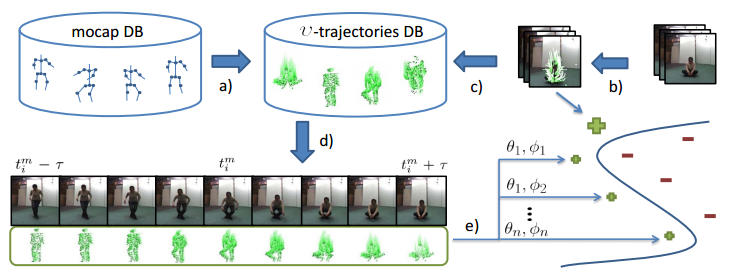
3d pose from motion
Ankur Gupta*, Julieta Martinez*, James J. Little, Robert J. Woodham.
3D pose from motion for cross-view action recognition.
In CVPR 2014 (29.88% acceptance rate)
An approach to improving cross-view action recognition by retrieving mocap given video sequences.
Misc

DeepViz
My information visualization final project, taught by the wonderful Tamara Munzner. A javascript visualization tool for image retrieval (2015).

Efros and Leung JS
A javascript implementation of a classic method for texture synthesis (2015).
Pavlov is no simpleton
I tried to reproduce the results of a 1993 paper on evolutionary dynamics by Sigmund and Novak. I also wrote a blog post about it (2014).
rand()
I am/have served as a reviewer for CVPR, ECCV, ICCV, IROS, ICRA, NeurIPS, AAAI, IJCAI, CVIU, and TPAMI.
I have done science outreach with GIRLsmarts4tech and UBC women in science.
On the fall of 2014 I started organizing CVRG, the Computer Vision Reading Group at UBC.